About Me
Welcome!
I’m Wenyue Hua, senior researcher at Microsoft Research, AI Frontiers. I was a postdoctoral researcher at University of California, Santa Barbara, working with Prof. William Yang Wang (2024 - 2025). I obtained my Ph.D. degree from Rutgers University, New Brunswick (2020 - 2024). I’m honored to be advised by Prof. Yongfeng Zhang. I received MA in Linguistics at Rutgers in 2020 (proudly advised by Prof. Adam Jardine) and BA in Linguistics and Philosophy and BS in Mathematics at UCLA in 2018 (proudly advised by Prof. Edward Keenan).
My research interests lie in Large Language Models and its various application, such as LLM-based agent, multi-agent system, generative recommender system, LLM reasoning. I care about the decision-making ability, safety, and efficiency of LLM-based agents.
I am also Partner @ NICE AI TALK (https://nice-intl.github.io/). If you have any paper or project that you want to present, please contact nice.ai.academy@gmail.com
Collaboration & Mentoring
I welcome discussions about AI agents and am open to collaborations with researchers and industry professionals. I also enjoy mentoring students at various stages of their academic journey.
Feel free to email me a conversation at wenyue.hua@rutgers.edu to explore potential partnerships or discuss recent developments in the field.
- Large language models
- LLM-based agent
- Trustworthy AI
- Efficient AI
-
Postdoctoral Research in Computer Science, 2024-2025
Computer Science Department, University of California, Santa Barbara
-
Ph.D. in Computer Science, 2020-2024
Computer Science Department, Rutgers University, New Brunswick
-
Master of Arts in Linguistics (Ph.D. track transfer out), 2018-2020
Department of Linguistics, Rutgers University, New Brunswick
-
B.S. in Mathematics, General & B.A. in Linguistics&Philosophy with Specialization in Computing, 2014-2018
UCLA
News
Experience
- Advisor: Prof. William Yang Wang
- Dissertation: Trustworthy Large Language Model
- Advisor: Prof. Yongfeng Zhang
- Thesis: Learning Underlying Representations and Input-Strictly-Local Functions
- Advisor: Prof. Adam Jardine
- Thesis: Boolean-Algebraic Representation of Possible Worlds
- Advisor: Prof. Edward Keenan
Featured Publications
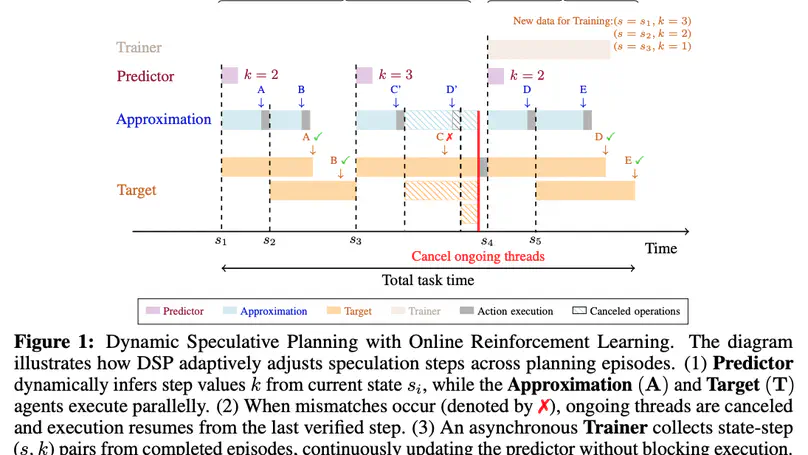
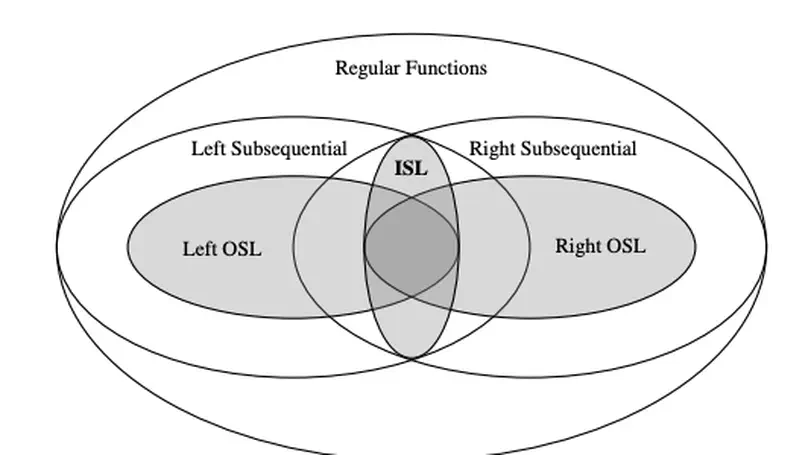
Large language models (LLMs) have shown remarkable improvements in reasoning and many existing benchmarks have been addressed by models such as o1 and o3 either fully or partially. However, a majority of these benchmarks emphasize deductive reasoning, including mathematical and coding tasks in which rules such as mathematical axioms or programming syntax are clearly defined, based on which LLMs can plan and apply these rules to arrive at a solution. In contrast, inductive reasoning, where one infers the underlying rules from observed data, remains less explored. Such inductive processes lie at the heart of scientific discovery, as they enable researchers to extract general principles from empirical observations. To assess whether LLMs possess this capacity, we introduce InductionBench, a new benchmark designed to evaluate the inductive reasoning ability of LLMs. Our experimental findings reveal that even the most advanced models available struggle to master the simplest complexity classes within the subregular hierarchy of functions, highlighting a notable deficiency in current LLMs’ inductive reasoning capabilities. Coda and data are available this url.