LLM-based Agent and Multi-agent System

Abstract
Artificial Intelligence (AI) aims to emulate Human Intelligence (HI) in combining basic skills to address complex tasks. AI agents is an especially important step the development of AI, which should integrate expert models and external tools for solving intricate problems, a step towards achieving Artificial General Intelligence (AGI). Large Language Models (LLMs) demonstrate notable capabilities in learning and reasoning and are proficient in employing external models, tools, plugins, or APIs for complex problem-solving. LLM-based agents are essentially LLMs enhanced with access to these additional resources.
Publications


This paper investigates the rationality of large language models (LLMs) in strategic decision-making contexts, specifically within the framework of game theory. We evaluate several state-of-the-art LLMs across a spectrum of complete-information and incomplete-information games. Our findings reveal that LLMs frequently deviate from rational strategies, particularly as the complexity of the game increases with larger payoff matrices or deeper sequential trees. To address these limitations, we design multiple game-theoretic workflows that guide the reasoning and decision-making processes of LLMs. These workflows aim to enhance the models’ ability to compute Nash Equilibria and make rational choices, even under conditions of uncertainty and incomplete information. Experimental results demonstrate that the adoption of these workflows significantly improves the rationality and robustness of LLMs in game-theoretic tasks. Specifically, with the workflow, LLMs exhibit marked improvements in identifying optimal strategies, achieving near-optimal allocations in negotiation scenarios, and reducing susceptibility to exploitation during negotiations. Furthermore, we explore the meta-strategic considerations of whether it is rational for agents to adopt such workflows, recognizing that the decision to use or forgo the workflow constitutes a game-theoretic issue in itself. Our research contributes to a deeper understanding of LLMs’ decision-making capabilities in strategic contexts and provides insights into enhancing their rationality through structured workflows. The findings have implications for the development of more robust and strategically sound AI agents capable of navigating complex interactive environments.Coda and data are available this url.
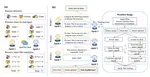
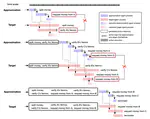
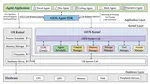
LLM-based intelligent agents face significant deployment challenges, particularly related to resource management. Allowing unrestricted access to LLM or tool resources can lead to inefficient or even potentially harmful resource allocation and utilization for agents. Furthermore, the absence of proper scheduling and resource management mechanisms in current agent designs hinders concurrent processing and limits overall system efficiency. As the diversity and complexity of agents continue to grow, addressing these resource management issues becomes increasingly critical to LLM-based agent systems. To address these challenges, this paper proposes the architecture of AIOS (LLM-based AI Agent Operating System) under the context of managing LLM-based agents. It introduces a novel architecture for serving LLM-based agents by isolating resources and LLM-specific services from agent applications into an AIOS kernel. This AIOS kernel provides fundamental services (e.g., scheduling, context management, memory management, storage management, access control) and efficient management of resources (e.g., LLM and external tools) for runtime agents. To enhance usability, AIOS also includes an AIOS-Agent SDK, a comprehensive suite of APIs designed for utilizing functionalities provided by the AIOS kernel. Experimental results demonstrate that using AIOS can achieve up to 2.1x faster execution for serving agents built by various agent frameworks. The source code is available at this url.


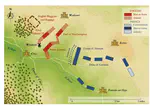
Can we avoid wars at the crossroads of history? This question has been pursued by individuals, scholars, policymakers, and organizations throughout human history. In this research, we attempt to answer the question based on the recent advances of Artificial Intelligence (AI) and Large Language Models (LLMs). We propose WarAgent, an LLM-powered multi-agent AI system, to simulate the participating countries, their decisions, and the consequences, in historical international conflicts, including the World War I (WWI), the World War II (WWII), and the Warring States Period (WSP) in Ancient China. By evaluating the simulation effectiveness, we examine the advancements and limitations of cutting-edge AI systems’ abilities in studying complex collective human behaviors such as international conflicts under diverse settings. In these simulations, the emergent interactions among agents also offer a novel perspective for examining the triggers and conditions that lead to war. Our findings offer data-driven and AI-augmented insights that can redefine how we approach conflict resolution and peacekeeping strategies. The implications stretch beyond historical analysis, offering a blueprint for using AI to understand human history and possibly prevent future international conflicts. Code and data are available at this url.

Human Intelligence (HI) excels at combining basic skills to solve complex tasks. This capability is vital for Artificial Intelligence (AI) and should be embedded in comprehensive AI Agents, enabling them to harness expert models for complex task-solving towards Artificial General Intelligence (AGI). Large Language Models (LLMs) show promising learning and reasoning abilities, and can effectively use external models, tools, plugins, or APIs to tackle complex problems. In this work, we introduce OpenAGI, an open-source AGI research and development platform designed for solving multi-step, real-world tasks. Specifically, OpenAGI uses a dual strategy, integrating standard benchmark tasks for benchmarking and evaluation, and open-ended tasks including more expandable models, tools, plugins, or APIs for creative problem-solving. Tasks are presented as natural language queries to the LLM, which then selects and executes appropriate models. We also propose a Reinforcement Learning from Task Feedback (RLTF) mechanism that uses task results to improve the LLM’s task-solving ability, which creates a self-improving AI feedback loop. While we acknowledge that AGI is a broad and multifaceted research challenge with no singularly defined solution path, the integration of LLMs with domain-specific expert models, inspired by mirroring the blend of general and specialized intelligence in humans, offers a promising approach towards AGI. We are open-sourcing the OpenAGI project’s code, dataset, benchmarks, evaluation methods, and the UI demo to foster community involvement in AGI advancement here this url.