LLM & NLP

Abstract
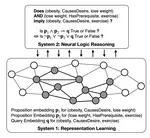
Large language models (LLMs) like OpenAI’s GPT series have revolutionized the field of natural language processing (NLP) by demonstrating an impressive ability to understand and generate human language. A key aspect of these models is their reasoning ability, which is a subject of growing interest and investigation. I am particularly focused on exploring the reasoning capabilities in LLMs. This includes understanding the mechanisms that facilitate reasoning within these models, assessing the extent to which LLMs are capable of conducting reasoning processes, and discerning between genuine reasoning and the mere mimicking of patterns observed in pre-trained data.
Publications
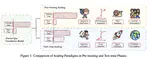
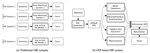
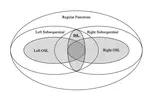
Large language models (LLMs) have shown remarkable improvements in reasoning and many existing benchmarks have been addressed by models such as o1 and o3 either fully or partially. However, a majority of these benchmarks emphasize deductive reasoning, including mathematical and coding tasks in which rules such as mathematical axioms or programming syntax are clearly defined, based on which LLMs can plan and apply these rules to arrive at a solution. In contrast, inductive reasoning, where one infers the underlying rules from observed data, remains less explored. Such inductive processes lie at the heart of scientific discovery, as they enable researchers to extract general principles from empirical observations. To assess whether LLMs possess this capacity, we introduce InductionBench, a new benchmark designed to evaluate the inductive reasoning ability of LLMs. Our experimental findings reveal that even the most advanced models available struggle to master the simplest complexity classes within the subregular hierarchy of functions, highlighting a notable deficiency in current LLMs’ inductive reasoning capabilities. Coda and data are available this url.
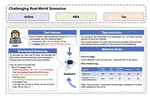
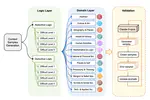
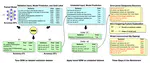
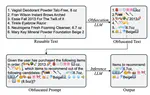
Cloud-based Large Language Models (LLMs) such as ChatGPT have become increasingly integral to daily operations. Nevertheless, they also introduce privacy concerns – firstly, numerous studies underscore the risks to user privacy posed by jailbreaking cloud-based LLMs; secondly, the LLM service providers have access to all user data, which deters individuals from confidently utilizing such services. To address such concerns, we propose a simple yet effective paradigm, EmojiPrompt, to protect user privacy. At its core, EmojiPrompt performs generative transformation, obfuscating private data within prompts with linguistic and non-linguistic elements before submitting them to cloud-based LLMs. We evaluate EmojiPrompt’s performance across 8 datasets from various domains. We also propose simulated inference attacks to assess EmojiPrompt’s ability to preserve user privacy. The results demonstrate that EmojiPrompt effectively obfuscates user private data, while largely maintaining, or even enhancing, performances compared to the unobfuscated version. Furthermore, EmojiPrompt’s atomic-level obfuscation allows it to function exclusively with cloud-based LLMs. For source code, please refer to this url.
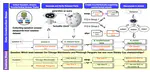
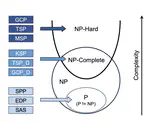
Complex reasoning ability is one of the most important features of current LLMs, which has also been leveraged to play an integral role in complex decision-making tasks. Therefore, the investigation into the reasoning capabilities of Large Language Models (LLMs) is critical – numerous benchmarks have been established to assess the reasoning abilities of LLMs. However, current benchmarks are inadequate in offering a rigorous evaluation of the full extent of reasoning abilities that LLMs are capable of achieving. They are also prone to the risk of overfitting, as these benchmarks, being publicly accessible and static, allow models to potentially tailor their responses to specific benchmark metrics, thereby inflating their performance. Addressing these limitations, our research introduces a new benchmark, named NPHardEval. This benchmark is designed to evaluate the reasoning abilities of LLMs across a broad spectrum of 900 algorithmic questions, extending up to the NP-Hard complexity class. These questions are meticulously chosen to represent a wide range of complexity class below the NP-hard complexity class, offering a rigorous measure of the reasoning ability of LLMs. Through this study, we shed light on the current state of reasoning in LLMs, providing an objective and rigorous perspective through the comparison of LLMs’ performance across complex classes. Moreover, this benchmark is designed with a dynamic update mechanism, where the datapoints are refreshed on a monthly basis. Such regular updates play a crucial role in mitigating the risk of LLMs overfitting to the benchmark, promoting a more accurate and reliable assessment of their reasoning capabilities. The benchmark dataset and code of NPHardEval are available at this https URL.