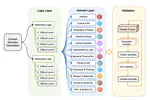
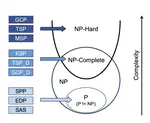
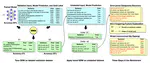
Complex reasoning ability is one of the most important features of current LLMs, which has also been leveraged to play an integral role in complex decision-making tasks. Therefore, the investigation into the reasoning capabilities of Large Language Models (LLMs) is critical – numerous benchmarks have been established to assess the reasoning abilities of LLMs. However, current benchmarks are inadequate in offering a rigorous evaluation of the full extent of reasoning abilities that LLMs are capable of achieving. They are also prone to the risk of overfitting, as these benchmarks, being publicly accessible and static, allow models to potentially tailor their responses to specific benchmark metrics, thereby inflating their performance. Addressing these limitations, our research introduces a new benchmark, named NPHardEval. This benchmark is designed to evaluate the reasoning abilities of LLMs across a broad spectrum of 900 algorithmic questions, extending up to the NP-Hard complexity class. These questions are meticulously chosen to represent a wide range of complexity class below the NP-hard complexity class, offering a rigorous measure of the reasoning ability of LLMs. Through this study, we shed light on the current state of reasoning in LLMs, providing an objective and rigorous perspective through the comparison of LLMs’ performance across complex classes. Moreover, this benchmark is designed with a dynamic update mechanism, where the datapoints are refreshed on a monthly basis. Such regular updates play a crucial role in mitigating the risk of LLMs overfitting to the benchmark, promoting a more accurate and reliable assessment of their reasoning capabilities. The benchmark dataset and code of NPHardEval are available at
this https URL.