Discover, Explanation, Improvement: Automatic Slice Detection Framework for Natural Language Processing
Abstract
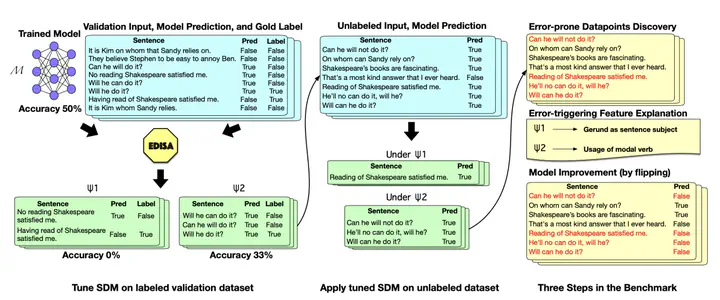
Current natural language processing (NLP) models such as BERT and RoBERTa have achieved high overall performance, but they often make systematic errors due to bias or certain difficult features to learn. Thus research on slice detection models (SDM) which automatically identifies underperforming groups of datapoints has gradually caught more attention, which aims at both understanding model behaviors and providing insights for future model training and designing. However, there is little systematic research on SDM and quantitative evaluation of its assessment for NLP models. Our paper fills this gap by proposing “Discover, Explanation, Improvement” framework that discovers coherent and underperforming groups of datapoints and unites datapoints of each slice under human-understandable concepts; it also provides comprehensive evaluation tasks and the corresponding quantitative metrics, which enable convenient comparison for future works. Results show that our framework can accurately select error-prone datapoints with informative semantic features that summarize error patterns, based on which it directly boosts model performance by an average of 2.85 points based on trained models without tuning any parameters across multiple datasets.
Wenyue Hua
Postdoctoral Researcher
Ph.D. in artificial intelligence, specifically focused on large language models.